At the heart of one of our major web applications at TigerLead is a property listing search. The search supports all the obvious criteria, like price range and bedrooms, more complex ones like school districts, plus a “full-text” search field.
This is the story of moving the property listing search logic from querying a PostgreSQL instance to querying an ElasticSearch cluster.The initial motivation for using ElasticSearch was to improve the full-text search feature. We’d been using the full text search features built into PostgreSQL which was functional but limited. I’m sure we could have made better use of it but we wanted to take a bigger leap forward.
At the time, early in 2012, we looked at various options, including Sphinx and Solr. Elasticsearch was new and relatively immature but had a compelling feature set and momentum. The availability of powerful feature-rich APIs for Perl, i.e., the ElasticSearch, ElasticSearch::SearchBuilder, and Elastic::Model modules, was also a key factor. We began to see Elasticsearch as not just a solution for full-text search but as a strategic technology, applicable to a wide range of applications.
I found the learning curve quite steep. There was little in the way of guides and tutorials at the time and the reference documentation was patchy and often assumed familiarity with the terminology for Lucene, the foundation that underlies both Solr and Elasticsearch. Thankfully the documentation and other resources have improved since then. Also many companies are using Elasticsearch now (github, stackoverflow, foursquare, soundcloud, Wajam and kickstarter, to name a few) and blogging about their experience of what to do and what not to do.
I’d especially like to thank Clinton Gormley for kindly giving me much help and support as I climbed the learning curve and stumbled over assorted issues.
Index Building
Our PostgreSQL database remains the ‘source of truth’. We build a new Elasticsearch index from the PostgreSQL data each day and feed changes into Elasticsearch every few minutes. Each new index has a name that includes the date and time it was created and we use aliases to route queries relating to subsets of the data to the appropriate index.
Index and alias definition and management, along with the loading of data, is managed via the delightful Elastic::Model module. (Clinton’s presentation is well worth a look.)
Aside: We’re exploring the use of PgQ for in-PostgreSQL transaction-safe queuing. That would let us keep Elasticsearch in sync in near-realtime in a more efficient way using triggers on relevant tables to queue change messages.
We only sync on-market property listings to Elasticsearch, of which there are millions across the US and Canada. Each has many numeric fields, many boolean fields, a number of text fields, plus a number of lists-of-integers fields.
Query Building
We use DBIx::Class as an abstract interface to the property listings in PostgreSQL, and that means using SQL::Abstract to construct the search query. So we have a module that, for each web search query parameter, adds the corresponding elements to the SQL::Abstract data structure.
Most are pretty trivial, like
$sql_abstract->{price} = { '>=' => $price_min };
Others are a little more tricky, like our basic textsearch query:
$sql_abstract->{ts_index_col} = { '@@' => \[ "plainto_tsquery(?)", [ ts_index_col => $plain_ft_query ] ] };
Elasticsearch has a very rich query language. It’s not actually a language at all, but something more like an Abstract Syntax Tree expressed in JSON. The Perl interface to this is the ElasticSearch::SearchBuilder. It looks a little like SQL::Abstract but is much richer.
I thought for a while about translating the SQL::Abstract data structure that we already generated into a corresponding ElasticSearch::SearchBuilder structure. In the end I decided this wouldn’t leave us in a good place. It proved better to modify every place that built the SQL::Abstract data structure to also build an ElasticSearch::SearchBuilder structure, tuned to the semantics of the field. For example, in some cases it can be better to use ‘lte‘ and ‘gte‘ instead of ‘<=‘ and ‘>=‘ as comparison operators.
Full Records or IDs Only?
Another early design decision was whether to store (and return) all the property details in Elasticsearch, or just enough to perform searches and return only IDs that could then be used to fetch the full details from PostgreSQL.
In the end I decided to store only search fields and return only IDs. The big downside was that every query would require two round-trips: one to query Elasticsearch to get the IDs and one to query PostgreSQL to get the full details. That might seem a little odd. The major motivation was how the new code would interface with the existing logic in the web application.
Execution
The existing code executed the listing search using the standard DBIx::Class search() method:
$c->model($schema_name)->search( $sqla, \%attr )
Here %attr contained two joins, two prefetches, paging, order by, cache control, and some extra fields via '+select'. The resulting resultset was then inflated via a series of five with_*() method calls based on DBIx::Class::ResultSet::WithMetaData (which was fashionable at the time the code was written).
At this stage using Elasticsearch was just an experiment and, frankly, I didn’t want to mess with all that code! Returning just IDs let me integrate Elasticsearch with hardly any changes.
The trick was to replace the $sqla data structure that had been constructed to perform the full search with one that would just fetch the IDs that had been returned by Elasticsearch:
$sqla = { 'me.id' => { -in => \@ids_from_es } };
There was a little fiddling with paging and ordering, but that trick was the heart of it making the integration quite simple.
Another benefit was that we have a simple way to recover from problems. If ES fails for any reason then we simply don’t alter $sqla, so the original query runs against PG.
Runtime Control
We needed to be able to soft-launch this, to enable it for only a subset of requests. We already had the infrastructure for that, so once the code was in production we could enable it for specific users and control the overall percentage of search requests using Elasticsearch.
This was obviously very useful but also, as it turned out, our initial timidness hid interesting performance behaviour.
Performance
Property search is a key feature of the service and performance was naturally a concern. Would the presumed benefits of Elasticsearch (ES) outweigh the cost of having to run two queries, on two different databases? I was fairly confident but not certain.
We were using a cluster of three ES nodes, each with 8GB memory and 4 CPUs. Once the code was ready I’d done some performance testing, firing randomly generated search requests at the web servers, in our staging environment. Those stress test results looked good.
When we started routing 2-5% of actual production search requests to ES, however, the results were not good. Here’s a chart of the performance of PostgreSQL (PG) in green with Elasticsearch+PostgreSQL (ES+PG) in red:
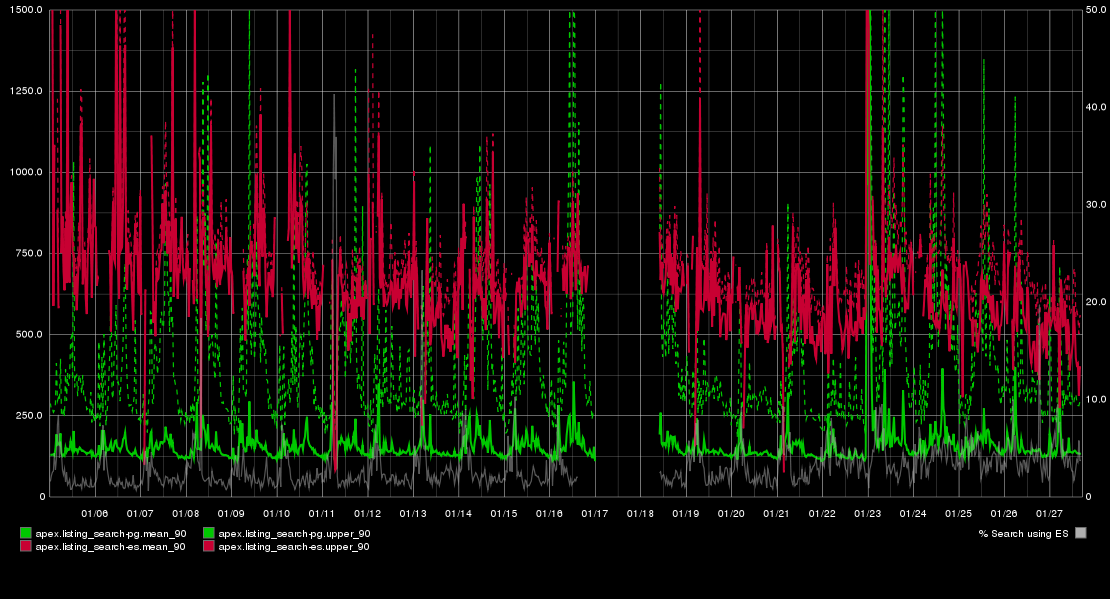
The mean search time using ES+PG was worse than the 90th percentile time for PG alone. That was disappointing and puzzling. I embarked on a review of all the (many) things that might not be optimal in the ES server configuration, in the mapping applied to the fields, and the particular way were we constructing the queries. Here Clinton Gormley was beyond helpful, again. We found and tuned many little things, which was great, but none were clearly the cause of the apparent slowness.
To cut a long story short, the cause turned out to be the fact we were running the ES nodes in virtual machines (KVM). More specifically, although we’d configured ES to lock the physical memory pages via bootstrap.mlockall=true, mlockall() within a guest operating system doesn’t stop the host operating system stealing the physical pages.
From the host’s point of view those memory pages weren’t busy enough to keep assigned to the ES VM, so the solution was simple: give more traffic to ES. Sure enough, as we increased the number of requests going to ES it got faster!
Here’s a chart showing the final ramp up from around 15% of requests going to ES up to 100%:

You can see that at 15% the mean and 90th percentile performance of ES+PG closely matched that of PG alone. At 100% ES+PG was not only clearly faster than PG alone, but the 90th percentile was close to the mean of PG alone. Since then we’ve upgraded ES to a more recent version and increased the memory on each node to 16GB. Now the mean search time is a steady 100ms and the 90th percentile hovers around 150ms.
Scalability
We’re using multicast discovery so there’s zero configuration. We can deploy a new server and the new Elasticsearch node will join the cluster and automatically distribute the data and query workload. It really is as simple as that.
Reliability
We’ve only had one problem that I can recall where Elasticsearch behaved strangely. Even that didn’t stop search requests, it only affected building a new index. Restarting the cluster fixed it.
That was with an early 0.20.x release and we’ve had no recurrence after upgrading. We’re on the latest 0.20.x now and plan to move to 0.90.x before long. (An upgrade that should significantly boost performance again.)
Next Steps
We’ve been impressed with Elasticsearch as a search solution, in terms of functionality, reliability and performance. Delighted by the support from Clinton and the IRC community. And amazed at the range of plugins being developed.
We’re pushing full listing data into Elasticsearch now, and writing modules to better abstract the searching so it can be used more easily in other applications. We’re also happily cooking up plans to use more Elasticsearch features, like percolate, in other projects.
